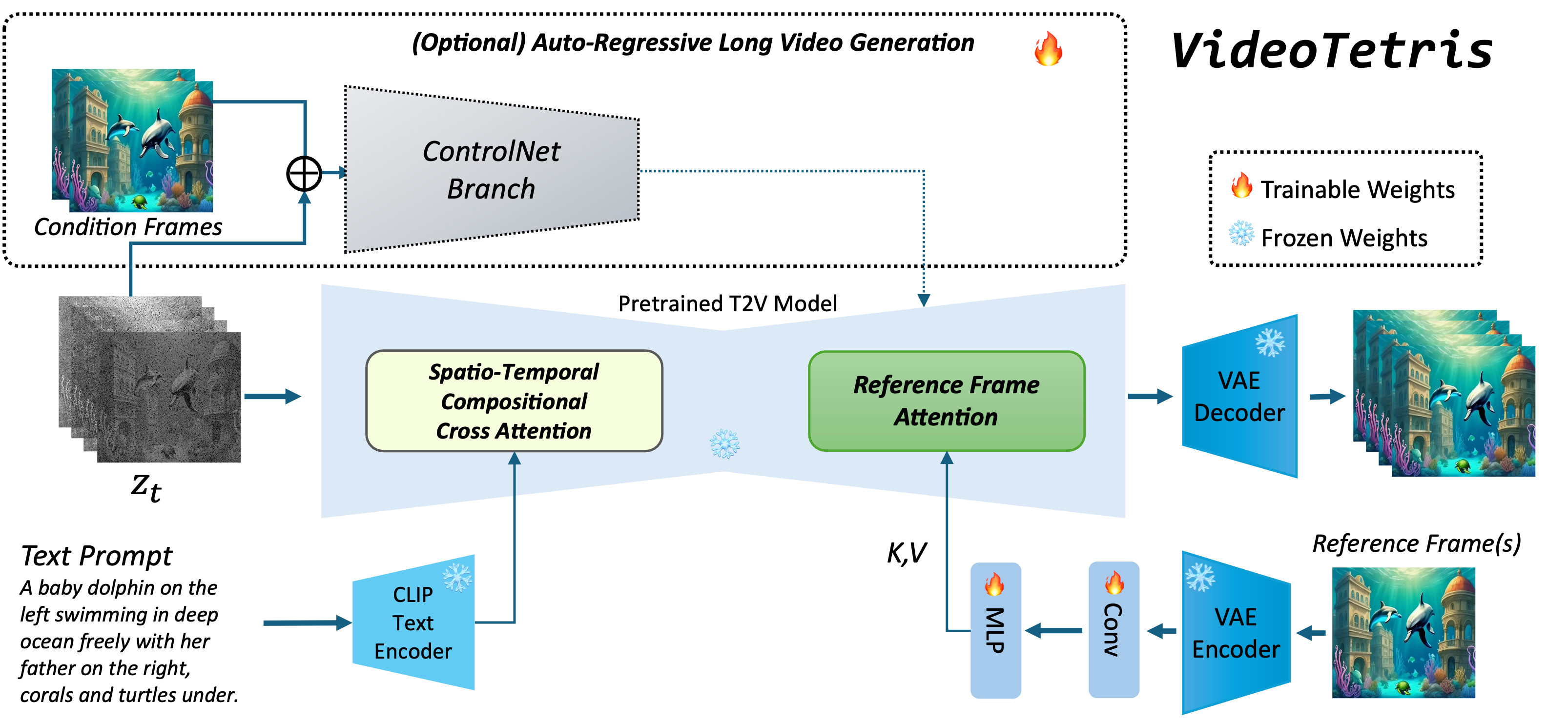
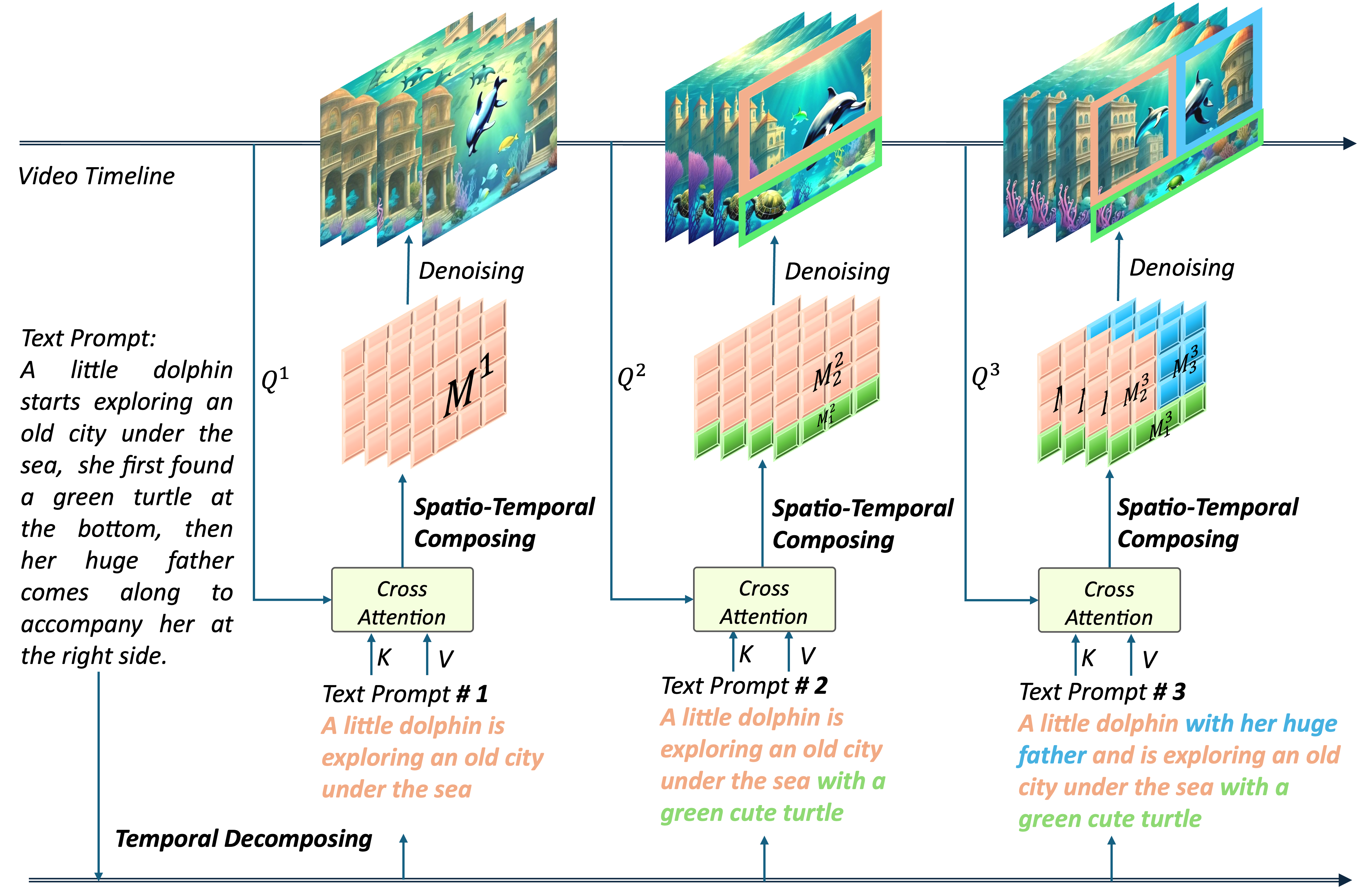
VideoTetris is a novel framework that enables compositional text-to-video generation. We identify compositional video generation in two scenarios: Video Generation with Compositional Prompts and Long Video Generation with Progressive Compositional Prompts. We compare VideoTetris with both short and long video generation models, and it showcases superior performance in compositional generation with the capability of precisely following position information, consistent scene transitions, and various features of different sub-objects.